What’s Really Behind Those AI Art Images?
What feels like magic is actually incredibly complicated and ethically fraught.

It’s been a while since a particular piece of technology has felt as fraught, efficient, and consequential as today’s text-to-image AI art-generation tools like DALL-E 2 and Midjourney. The reason for this is twofold: The tools continue to grow in popularity because they are fairly easy to use, and they do something cool by conjuring almost any image you can dream up in your head. When a text prompt comes to life as you envisioned (or better than you envisioned), it feels a bit like magic. When technologies feel like magic, adoption rates tick up rapidly. The second (and more important) reason is that the AI art tools are evolving quickly—often faster than the moral and ethical debates around the technology. I find this concerning.
In just the last month, the company Stability AI released Stable Diffusion: a free, open-source tool trained off of three massive datasets, including more than 2 billion images. Unlike DALL-E or Midjourney, Stable Diffusion has none of the content guardrails to stop people from creating potentially problematic imagery (incorporating trademarked images, or sexual or potentially violent and abusive content). In short order, a subset of Stable Diffusion users generated loads of deepfake-style images of nude celebrities, resulting in Reddit banning multiple NSFW Stable Diffusion communities. But, because Stable Diffusion is open-sourced, the tool has been credited with an “explosion of innovation”—specifically in regard to people using the tool to generate images from other images. Stability AI is pushing to release AI tools for audio and video soon, as well.
I’ve written twice about these debates and even found myself briefly near the center of them. Then and now, my biggest concern is that the datasets that these tools are trained off of are full of images that have been haphazardly scraped from across the internet, mostly without the artists’ permission. Making matters worse, the companies behind these technologies aren’t forthcoming about what raw materials are powering their models.
Thankfully, last week the programmer/bloggers Andy Baio and Simon Willison pulled back the curtain, if only a bit. Because Stable Diffusion’s dataset is an open model, the pair lifted data for 12 million images from part of Stable Diffusion’s dataset, and made a browsing tool that allows anyone to search through those images. While Baio and Willison’s dataset is just a small fraction of Stable Diffusion’s full set of 2.3 billion images, there’s a great deal we can learn from this partial glimpse. In a very helpful blog post, Baio notes that “nearly half of the images” in their dataset came from only 100 domains. The largest number of images came from Pinterest—over a million in all. Other prominent image sources include shopping sites, stock-image sites, and user-generated-content sites like WordPress, Flickr, and DeviantArt.
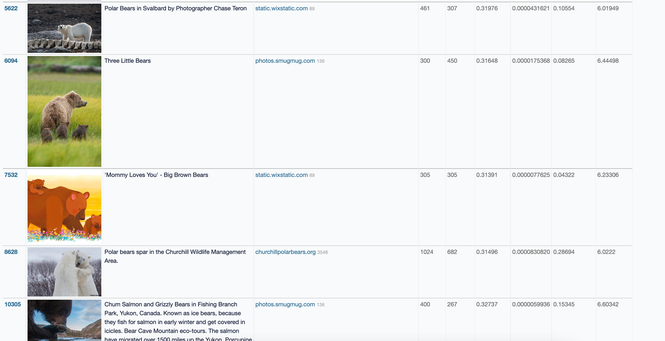
Baio and Willison’s dataset tool also lets you sort by artist. Here’s one of Baio’s findings:
Of the top 25 artists in the dataset, only three are still living: Phil Koch, Erin Hanson, and Steve Henderson. The most frequent artist in the dataset? The Painter of Light™ himself, Thomas Kinkade, with 9,268 images.
Once the tool went public, I watched artists on Twitter share their search findings. Many of them remarked that they had found a few examples of their own work, which had been collected and incorporated into Stable Diffusion’s dataset without their knowledge—possibly because a third party had shared them on a site like Pinterest. Others remarked that there was a wealth of copyrighted material in the dataset, enough to conclude that the AI art–ethics debate will almost certainly get tied up in the legal system at some point.
Damn, 3 of my paintings came up. https://t.co/FYDCQu2fqn
— Mariya Olshevska (@mariyaolshevska) September 1, 2022
I’ve spent multiple hours searching through Baio and Willison’s tool, and it's an odd experience that feels a bit like poking around the backstage of the internet. There is, of course, a wealth of NSFW content, and photos of lots and lots of female celebrities. But what stands out the most is just how random the collection is. It’s not really organized; it’s just a massive collection of images with robotic text descriptions. That’s because Stable Diffusion is based on enormous datasets collected by a whole other company: a nonprofit called LAION. And here’s where things get dicey.
As Baio notes in his post, LAION’s computing power was funded in large part by Stability AI. To complicate matters, LAION’s datasets are compiled by Common Crawl, a nonprofit that scrapes billions of web pages every month to aid in academic web research. Put another way: Stable Diffusion helped fund a nonprofit and gained access to a dataset that is largely compiled using a different academic nonprofit’s dataset, in order to build out a commercial tech product that takes billions of randomly gathered images (many of them the creative work of artists) and turns them into art that may be used to replace those artists’ traditionally commissioned artwork. (Gah!)
Looking through Baio and Willison’s dataset made me feel even more conflicted about this technology. I know that Baio shares a lot of my concerns as well, so I reached out to him to talk a bit about the project and what he learned. He said that, like me, he’s been fascinated by the way that the AI-art debate was immediately drafted into the internet’s long-running culture wars.
“You see the techno-utopians taking the most generous interpretation of what’s going on, and then you have other communities of artists taking the least-generous interpretation of these tools,” Baio said. “I attribute that to the fact that these tools are opaque. There’s a vacuum of information about how these tools are made, and people fill that vacuum with feelings. So we’re trying to let them see what’s in there.”
Baio told me that poking through the model gave him some clarity about where these images came from—including showing how the dataset is the product of tools initially built for academic use. “This scraping process makes things difficult,” he said. “If you’re an artist, you can stop Common Crawl from scraping your site. But so many of those images are coming from sites like Pinterest, where other people upload the content. It’s not clear how an artist could stop Common Crawl from scraping Pinterest.”
The more Baio has learned about the dataset, the thornier the potential legal, ethical, and moral questions grow. “People can’t agree on what is fair use in the best of times,” he said. “You have judges in different circuits arguing and interpreting it differently.”
Baio continued:
Asking, Is this use-case transformative? is so subjective, and these new tools only exacerbate the issue. You have to ask all these subjective questions like, Did this tool affect the market for an artist’s work? And when we talk about market value, are we talking about the market value for the artist’s piece of work that’s used in the dataset, or are we talking about the market value of that artist's ability to do future work? These questions are hard.
To further complicate the matter, Baio told me that even if we can see which images trained the AI model, we still can’t tell how the images affect what the model draws. “The most jaw-dropping thing about the whole world of text-to-image AI,” he said, “is that you have like 100 terabytes of images [that] get compressed way down to a 2 gigabyte file.”
Baio explained to me that the images aren’t stored inside these models. Instead, each model is composed of the inferences that the technology has made by relating all the trained images and their accompanying text to each other. “It’s extremely hard to wrap one’s head around,” he said. “if you incrementally add one image to the model, it’s minutely shifting around these relationships—these floating points of information—and changing in small ways.”
I’m no expert at all, but that description is reminiscent of how a memory works—that is, if a memory were perfectly photographic and able to capture and immediately process and recall billions of data points in milliseconds. Of course, human brains don’t behave in this way, and they certainly don’t operate at this scale—that is, rendering art in seconds for millions of users around the world—which is precisely what makes this technology so potentially powerful and fraught.
But Baio argues that, because these models operate this way, they complicate the conversation about the technology’s “transformative use.” What muddies the waters is that the model is not just mashing two or three images together.
“While it’s absolutely true that this AI art couldn’t exist if it weren’t trained on copyrighted images and the work of artists, the end result is something we don’t have a precedent or parallel for,” Baio told me. “This technology is a black-box machine that generates high-quality imagery endlessly. Now, maybe a court looks at this and says ‘It’s transformative use,’ and the can of worms is allowed to stay open. But databases have been found to be copyrightable, too. I just don’t know.”
But Baio believes the technology is too disruptive not to end up in court. Take stock-image companies, for example. It seems clear that AI art tools will absolutely disrupt these companies’ business models, and at least one of the AI art tools has scraped a stock-image site for its dataset.
“It would not surprise me to see one of these companies take an AI company to court,” Baio said.
The future of text-to-image generation tools is anything but certain. Although I have serious doubts that the legal system is going to act fast enough to constrain the rise of this technology, as Baio notes, it’s entirely possible that these tools could eventually get kneecapped if a litigious actor puts forth a compelling case. “What’s important to note here is that we are at Day One of these debates,” Baio reminded me. “And anybody who tells you they know where it will fall is wrong.”
It’s this idea—that we’re at the very beginning of a long, complicated debate over these tools and how they’re built and used—that has me riveted. I do not believe, as some do, that these tools will destroy art altogether, though I think they will be disruptive and may very well cause pain for some of the people whose work was used to feed the models. Right now, I look at these tools with a genuine sense of wonder for what they produce (I want to be clear that I also really enjoy playing around with them in a way that I haven’t enjoyed a technology in some time), and a deep, nagging concern for the way they’re being developed—in some cases by people like Stability AI’s founder, Emad Mostaque, who seems wholly dismissive of any of the ethical dilemmas of the technology.
We’re going to have countless arguments over the future of these types of models, and how to harness them in ways that delight us without fully exploiting and devaluing the labor of others. I have no idea whether we’ll be able to strike that balance as a society (it seems impossible if we simply let these tools scrape imagery with no guardrails). But the only way we have a chance at developing these tools in less exploitative or problematic ways is if we know how the technologies work.
What makes Baio and Willison’s work so valuable is that they’ve begun to help us understand what it is we’re arguing about when we talk about these tools. I think by pulling back the curtain on just a sliver of one of these models, it’s easier to see that this newer frontier of commercial AI art is being developed off the backs of huge corpuses of imagery that have been procured in ethically dubious ways. Once again, we’re looking at a powerful piece of technology that feels more concerned with pushing the boundaries of what it can do than what it ought to do. Of course, it doesn’t have to be this way. How we choose to reject or embrace or constrain this technology is an open question, and I find that fascinating, exciting, and a bit terrifying.
If you're interested, here are some past editions of Galaxy Brain where I've explored AI art:
 Charlie Warzel
Charlie Warzel Charlie Warzel
Charlie Warzel